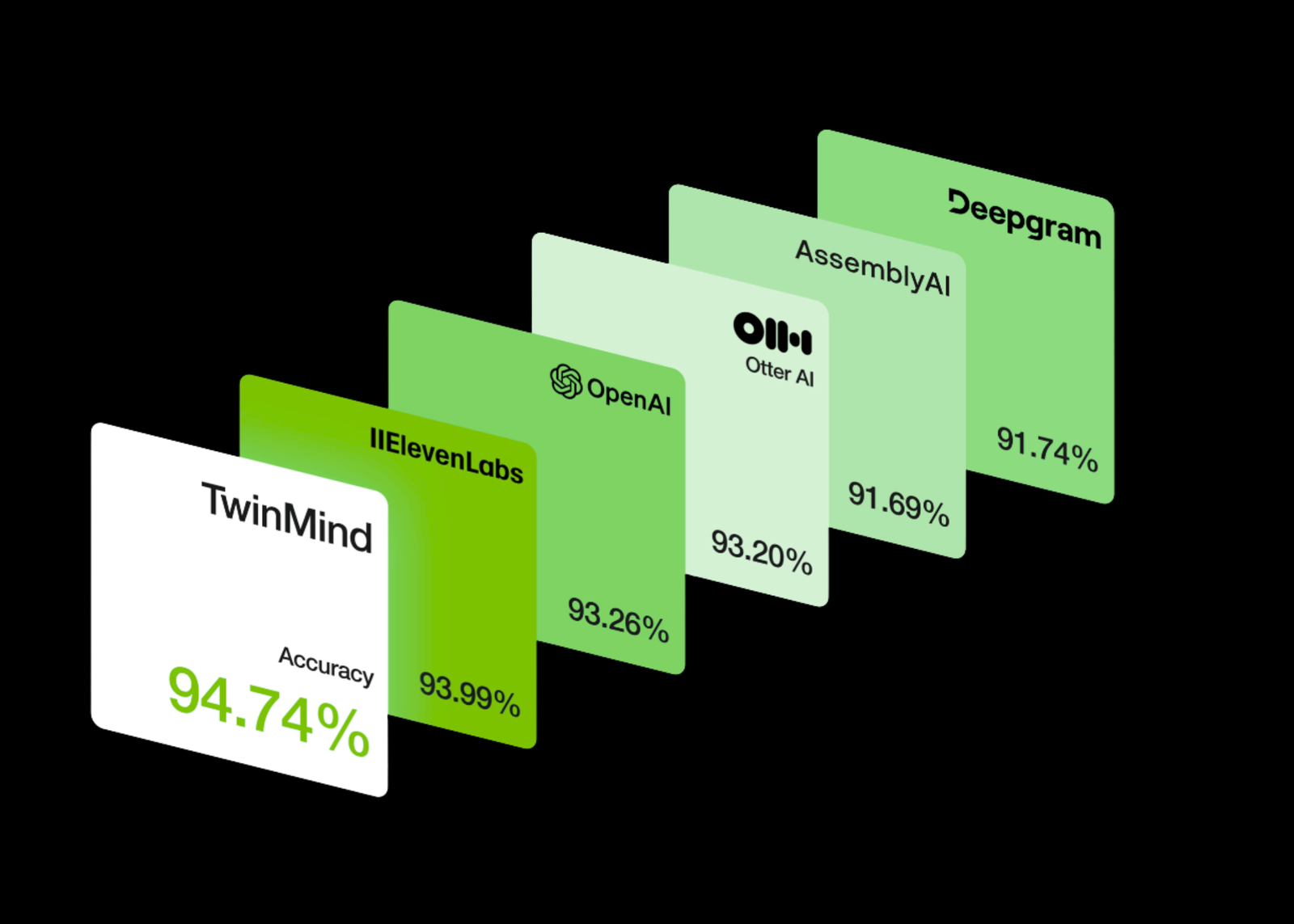
TwinMind, a California-based Voice AI startup, unveiled Ear-3 speech-recognition mannequin, claiming state-of-the-art efficiency on a number of key metrics and expanded multilingual help. The discharge positions Ear-3 as a aggressive providing towards present ASR (Computerized Speech Recognition) options from suppliers like Deepgram, AssemblyAI, Eleven Labs, Otter, Speechmatics, and OpenAI.
Key Metrics
| Metric | TwinMind Ear-3 Outcome | Comparisons / Notes |
|---|---|---|
| Phrase Error Charge (WER) | 5.26 % | Considerably decrease than many opponents: Deepgram ~8.26 %, AssemblyAI ~8.31 %. |
| Speaker Diarization Error Charge (DER) | 3.8 % | Slight enchancment over earlier greatest from Speechmatics (~3.9 %). |
| Language Help | 140+ languages | Over 40 extra languages than many main fashions; goals for “true world protection.” |
| Value per Hour of Transcription | US$ 0.23/hr | Positioned as lowest amongst main companies. |
Technical Method & Positioning
- TwinMind signifies Ear-3 is a “fine-tuned mix of a number of open-source fashions,” educated on a curated dataset containing human-annotated audio sources resembling podcasts, movies, and movies.
- Diarization and speaker labeling are improved through a pipeline that features audio cleansing and enhancement earlier than diarization, plus “exact alignment checks” to refine speaker boundary detections.
- The mannequin handles code-switching and blended scripts, that are sometimes troublesome for ASR methods as a result of different phonetics, accent variance, and linguistic overlap.
Commerce-offs & Operational Particulars
- Ear-3 requires cloud deployment. Due to its mannequin dimension and compute load, it can’t be totally offline. TwinMind’s Ear-2 (its earlier mannequin) stays the fallback when connectivity is misplaced.
- Privateness: TwinMind claims audio just isn’t saved long-term; solely transcripts are saved domestically, with optionally available encrypted backups. Audio recordings are deleted “on the fly.”
- Platform integration: API entry for the mannequin is deliberate within the coming weeks for builders/enterprises. For finish customers, Ear-3 performance shall be rolled out to TwinMind’s iPhone, Android, and Chrome apps over the subsequent month for Professional customers.
Comparative Evaluation & Implications
Ear-3’s WER and DER metrics put it forward of many established fashions. Decrease WER interprets to fewer transcription errors (mis-recognitions, dropped phrases, and so forth.), which is important for domains like authorized, medical, lecture transcription, or archival of delicate content material. Equally, decrease DER (i.e. higher speaker separation + labeling) issues for conferences, interviews, podcasts — something with a number of contributors.
The worth level of US$0.23/hr makes high-accuracy transcription extra economically possible for long-form audio (e.g. hours of conferences, lectures, recordings). Mixed with help for over 140 languages, there’s a clear push to make this usable in world settings, not simply English-centric or well-resourced language contexts.
Nonetheless, cloud dependency might be a limitation for customers needing offline or edge-device capabilities, or the place information privateness / latency considerations are stringent. Implementation complexity for supporting 140+ languages (accent drift, dialects, code-switching) could reveal weaker zones below hostile acoustic situations. Actual-world efficiency could differ in comparison with managed benchmarking.
Conclusion
TwinMind’s Ear-3 mannequin represents a powerful technical declare: excessive accuracy, speaker diarization precision, intensive language protection, and aggressive price discount. If benchmarks maintain in actual utilization, this might shift expectations for what “premium” transcription companies ought to ship.
Take a look at the Project Page. Be at liberty to take a look at our GitHub Page for Tutorials, Codes and Notebooks. Additionally, be happy to comply with us on Twitter and don’t neglect to affix our 100k+ ML SubReddit and Subscribe to our Newsletter.
Michal Sutter is an information science skilled with a Grasp of Science in Knowledge Science from the College of Padova. With a stable basis in statistical evaluation, machine studying, and information engineering, Michal excels at remodeling complicated datasets into actionable insights.